Bazy klucz-wartość
Bazy klucz-wartość to proste hashmapy, pozwalające zapisać i odczytać umieszczone pod określonym kluczem – identyfikatorem, dowolne dane, często poświęcające trwałość w celu uzyskania wyższej szybkości (potwierdzenie zapisu danych po zapisie do pamięci operacyjnej, przed zapisem do pamięci masowej). Wykorzystywane są one głównie do przechowywania danych tymczasowych – cache obiektów z właściwej bazy danych, przechowywanie sesji zalogowanych użytkowników, czy zawartości ich koszyków zakupowych.
Riak
- Zawartość: Typowy key-value store – nie wnika w wartość, jest to dla niego blob, aczkolwiek istnieją rozszerzenia (Riak Search) pozwalające na przeszukiwanie wartości. Biblioteki klienckie zajmują się serializacją i deserializacją danych. Najczęściej pojedynczy bucket odpowiada pojedynczej serializowanej klasie. Poszczególne wartości mogą wygasać po zadanym czasie.
- Komunikacja: REST API (CRUD)
- Dostęp: Baza danych ➔ Bucket ➔ Klucz ➔ Wartość
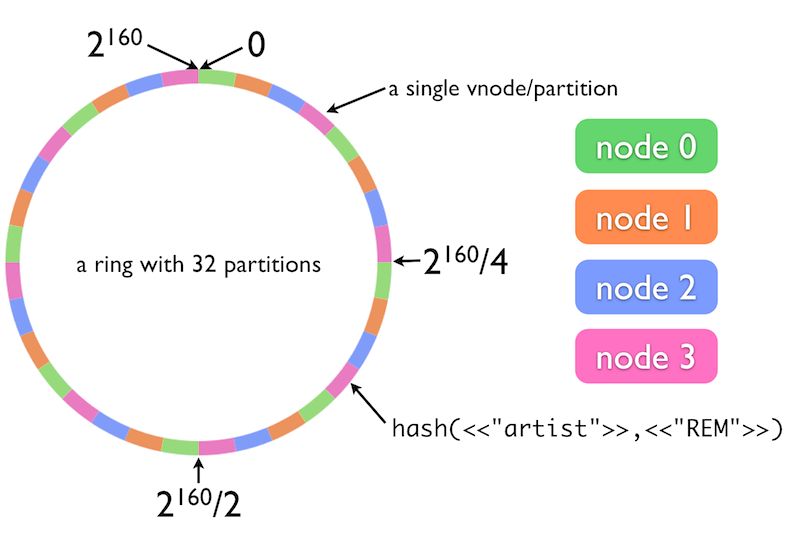
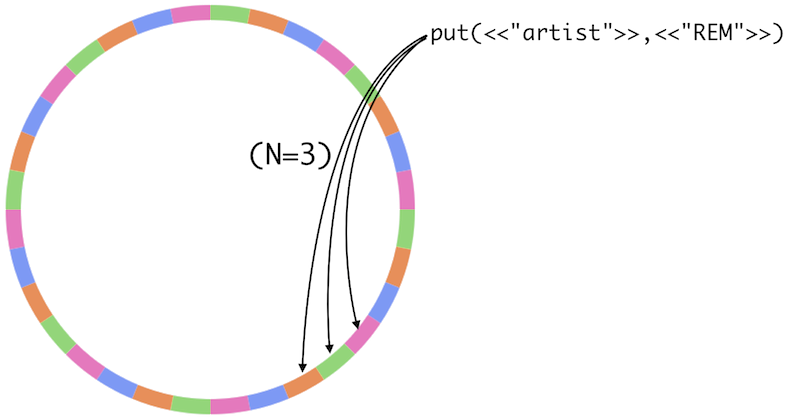
- Skalowanie/architektura klastra: Istnieje klaster z automatyczną replikacją i shardingiem. Przestrzeń wszystkich możliwych hashy kluczy dzielona jest na X partycji, następnie partycje te przydzielane są w cyklu round-robin kolejnym węzłom klastra, tak, że każdy węzeł odpowiada za przechowywanie danych z co X-tej partycji. np. klaster może być podzielony na 32 partycje i składać się z 4 węzłów – wtedy każdy z nich obsługuje po 8 “ułożonych naprzemiennie” partycji (ilustracja nr 1). W trakcie zapisu dane umieszczane są na N kolejnych partycjach (obsługiwanych przez N kolejnych węzłów, ilustracja nr 2). Użytkownik w celu zapisu lub odczytu, może połączyć się z dowolnym węzłem klastra. Więcej informacji tutaj.
- Spójność: Tworząc bucket decydujemy ile ma mieć replik [N] (na ilu kolejnych partycjach ma być zapisany każdy klucz) oraz na ile potwierdzeń zapisu oczekujemy [W], z ilu replik [R] odczytujemy dane (j/w) oraz co ma się stać, jeśli w trakcie zapisu nastąpi inny zapis do tego samego klucza na innym serwerze (wygrywa najnowszy po synchronizacji lub zapisywane są obie wersie klucza ze znacznikiem czasowym).
- Trwałość: Konfigurując bucket, oprócz ustawienia parametru [W] mówiącego nam o tym, na ile potwierdzeń zapisu oczekujemy, możemy także ustawić parametr [DW], mówiący o tym, ile replik ma potwierdzić zapis danych do pamięci masowej, zanim uznamy zapis za wykonany. Więcej informacji tutaj.
- Transakcje: Brak. Atomowe zmiany w obrębie jednego dokumentu.
Redis
- Zawartość: Oprócz podstawowej hashmapy klucz -> wartość, mapującej klucz na bloba, posiada różne typy danych – listy/kolejki, zagnieżdżone hashmapy, zbiory oraz wiele funkcji operujących na tych typach, a także mechanizm publish-subscribe. Klucze w głównej hashmapie mogą wygasać po zadanym czasie.
- Komunikacja: TCP oraz plaintekstowy własnościowy protokół.
- Dostęp: Nr bazy danych (0-15) ➔ klucz ➔ wartość (lub w przypadku podstruktur: klucz podstruktury, nr elemetu, element początkowy, końcowy, etc. ➔ wartość)
- Skalowanie/architektura klastra:
Dawniej: Replikacja master-slave, konfigurowana ręcznie. Sharding realizowany poprzez obecność wielu niezależnych baz do których bezpośrednio odwołuje się klient.
Obecnie: Do zarządzania replikacją – wybór nowego mastera w przypadku awarii i rekonfiguracja pozostałych węzłów, a także zwracanie klientowi informacji o aktualnej konfiguracji klastra, stosuje się rozwiązanie Redis Sentinel. Do automatycznego shardingu – Redis Cluster. - Spójność: Replikacja asynchroniczna master-slave, powoduje, że dane zapisane na masterze mogą być nowsze, niż te pobierane z serwera slave. Podczas zapisu nie decyduje się, na ilu replikacja musi się on odbyć, aby uznać dane za zapisane, podobnie, podczas odczytu, odpytuje się jedynie jeden serwer (master, lub slave, aby odciążyć master-a zapytaniami).
- Trwałość: Dane przechowywane są w pamięci RAM i tylko okresowo zapisywane na dysk.
- Transakcje: Brak
Inne
- Memcached
- Berkeley DB
- Hamster DB
- Amazon DynamoDB
- Project Voldemort
Bazy dokumentów
W przeciwieństwie do baz klucz-wartość, bazy te rozumieją zawartość – dokumenty umieszczane w polu wartość i pozwalają wykonywać na nich zapytania. Są one zamiennikiem baz SQL – pozwalają przechowywać trwałe dane, są wykorzystywane do przechowywania logów, danych w systemach CMS, blogach, czy sklepach internetowych. Zorientowane są jednak na agregacje, zamiast relacji – często odczytywane razem dokumenty umieszcza się wewnątrz innych dokumentów (np. komentarze w artykułach).
MongoDB
- Zawartość: W bazie umieszczane są dokumenty JSON, mogące zawierać zagnieżdżone hashmapy, czy listy oraz różne wartości (int, float, string, czy data). Każdy dokument w kolekcji może mieć inną strukturę. Podobnie jak w bazach klucz-wartość, umieszczane są one pod odpowiednim identyfikatorem – pole “_id”. Baza ta rozumie zawartość dokumentów, pozwala wykonywać zapytania wybierające odwołujące się do tych pól, czy zmieniające tylko niektóre pola, w określony sposób. Baza ta zoptymalizowana jest pod kątem agregacji (dane często odczytywane razem umieszczamy w poddokumentach – np. artykuły wraz z komentarzami), a nie relacji, mimo iż są one wspierane. Możliwe jest wykonanie zapytań agregujących dane w inny sposób niż zostało to przewidziane w trakcie projektowania bazy, z wykorzystaniem agreggation pipelines (prostsze operacje, np. zliczenie wszystkich komentarzy pod artykułami z danej kategorii) oraz algorytmu map-reduce (np. zrzucenie wszystkich komentarzy [danego użytkownika lub z danego roku], na płaską listę). Więcej informacji na temat aggregation pipelines i map-reduce, można znaleźć w oficjalnej dokumentacji. Wspierane są indeksy, po których możliwe jest łatwe filtrowanie (w tym wyszukiwanie pełnotekstowe), a także ograniczające – np. unique. Indeksy można zakładać na grupy pól.
- Komunikacja: Zapytania wykonywane są przy pomocy JSON-owego języka zapytań.
- Dostęp: Baza danych ➔ Kolekcja ➔ Dokument i jego pola
- Skalowanie/architektura klastra: Zestaw replik (replica set), w których jeden serwer jest masterem, a pozostałe slaveami. Wybór następuje automatycznie, zapis odbywa się tylko do aktualnego mastera, odczyt może być realizowany ze slaveów. Nad zestawami replik (lub pojedynczymi serwerami bez replikacji) można zrealizować sharding – wtedy oprócz wielu zestawów replik/serwerów, należy skonfigurować router lub wiele routerów zapytań (mongos) oraz serwery przechowujące konfigurację klastra (zestaw replik lub pojedynczy serwer). Sharding realizowany jest na podstawie wybranych kluczy. Za rozmieszczenie danych pomiędzy klastrami odpowiada balancer. Przy pomocy stref można powiązać dane wartości klucza shardującego z konkretnymi shardami, dzięki czemu można umieścić dane blisko ich użytkowników. W pojedynczej bazie mogą znajdować się zshardowane i niezshardowane kolekcje, wtedy niezshardowane dane dla danej bazy znajdują się w jej shardzie podstawowym. Opis architektury klastra i jego komponentów znajduje się tutaj i tutaj.
- Spójność: Podczas tworzenia klastra decydujemy ile replik ma znajdować się w danym shardzie oraz ile ma być shardów. Podczas wykonywania zapisu określamy na ile serwerów czekać (wszystkie, większość, żaden) oraz czy czekać, aż nastąpi zapis na dysku. Odczytując, decydujemy, czy zapis może być dokonany z serwera slave (możliwe nie najnowsze dane). Parametry te możemy ustawić dla operacji, kolekcji lub całego połączenia z bazą.
- Trwałość: J/W – możemy oczekiwać na zapis na dysku.
- Transakcje: Istnieją. Więcej informacji tutaj i tutaj.

Inne
- CouchDB
- Terrastore
- OrientDB
- RavenDB
Bazy rodziny kolumn
Bazy rodziny kolumn pod względem zawartości podobne są do baz SQL, mamy tutaj tabele, zawierające kolumny oraz wiersze. Nie każdy wiersz musi mieć uzupełnioną każdą kolumnę, przez co wiersze jednej tabeli nadal mogą mieć różne struktury. Baza nadal zorientowana jest na agregacje, a nie relacje – przechowujemy wiele tabel powtarzających się danych (denormalizacja oraz widoki zmaterializowane z wykorzystaniem map-reduce) lub “poddokumenty” umieszczone w zagnieżdżonych zbiorach/listach/słownikach, zamiast danych połączonych relacyjnie.
Apache Cassandra
- Zawartość: W nomenklaturze Cassandry baza nazywana jest przestrzenią kluczy, a tabela – rodziną kolumn. Kolumna w bazie może być superkolumną – zawierać zagnieżdżone kolumny (np. dane adresowe trzymane przy użytkowniku). Może ona także przyjmować jeden z wielu typów danych lub kolekcje (hashmapy, zbiory czy listy). Kolumny definiuje się w trakcie tworzenia rodziny kolumn. W danym wierszu nie wszystkie kolumny muszą istnieć (być wypełnione) i przez to bardzo łatwo je dodawać. Na kolumny nakłada się indeksy. Tylko po kolumnach posiadających indeks można filtrować dane w klauzuli WHERE. Zalecane jest korzystanie jedynie z indeksu podstawowego i dublowanie danych lub umieszczanie ich wewnątrz kolekcji. Każde pole w wierszu ma zapisany timestamp aktualizacji.
- Komunikacja: Do komunikacji z bazą wykorzystywany jest język zapytań CQL, podobny do języka SQL, jednak znacznie bardziej ograniczony – nie wspierający relacji i wielu innych operacji.
- Dostęp: Przestrzeń kluczy ➔ Rodzina kolumn ➔ Wiersz (po kluczu głównym) ➔ Kolumna ➔ Wartość
- Skalowanie/architektura klastra: Istnieje klaster składający się z węzłów zgrupowanych w centra danych. Klaster obsługuje replikacje oraz sharding. Podczas tworzenia przestrzeni kluczy definiujemy liczbę jej replik (oraz strategie – prostą lub pozwalającą nam zdefiniować liczbę replik osobno dla konkretnych centrów danych).
- Spójność: Zarówno dla odczytu, jak i zapisu, precyzujemy poziom spójności: all, quorum lub one. Podczas tworzenia rodziny kolumn precyzujemy jak dużo chcemy mieć replik danych – dane nie muszą być zapisywane na wszystkich serwerach klastra.
- Trwałość: Dane przed zapisem na dysk przechowywane są w pamięci (Mem-Table), po przepełnieniu bufora (zebraniu większej liczby rekordów), zapisywane są one na dysku (w plikach Sorted-String Table). Oprócz zapisu do Mem-Table, prowadzony jest również commit log, zapisywany na dysk i umożliwiający odtworzenie niezapisanych danych po awarii. W trakcie tworzenia przestrzeni kluczy, możemy też włączyć natychmiastowy zapis danych na dysk (przed potwierdzeniem wykonania zapytania).
- Transakcje: Brak, możliwość wykorzystania zewnętrznych bibliotek – zookeeper, cages.
Inne
- HBase
- Hypertable
- Amazon SimpleDB