1. Wprowadzenie do Linuksa i pracy w laboratorium
W trakcie zajęć zapoznaliśmy się z podstawami poruszania się w środowisku Linux – poleceniami mkdir, cd, touch, pwd, whoami, cat, ls, mv, rm, cp, adresowaniem względnym i bezwzględnym oraz edytorami vim, mcedit i nano. Omówiliśmy także sposób zdalnego logowania się do laboratoryjnego serwera na którym wykonywać będziemy zadania. Ponieważ w sprawozdaniu opisać mieliśmy jedynie nowe dla nas zagadnienia, a ja na co dzień korzystam z systemu Linux, pozwolę sobie pominąć tą część.
2. Kompilacja w konsoli, linkowanie, program make i plik Makefile
Aby przećwiczyć kompilację programów w konsoli, napisaliśmy prosty program wyświetlający napis “Hello World!” w języku C i skompilowaliśmy go ręcznie wywołując polecenia:
gcc -c plik.c
gcc -o plik plik.oNastępnie utworzyliśmy plik Makefile służący do automatyzacji procesu kompilacji. Jest on często wykorzystywany w dużych projektach zawierających wiele plików z kodem źródłowym, w przypadku których istnieją zależności które pliki muszą zostać skompilowane/zlinkowane przed innymi.
Składnia pliku Makefile:
plik1: plik2
polecenia
plik2: plik3
poleceniaOpis składni:
- plik1 (w pierwszej sekcji) to plik który chcemy uzyskać,
- plik2 (w pierwszej sekcji) jest do tego potrzebny (w tym miejscu może znajdować się lista wielu plików),
- polecenia to lista Unixowych poleceń wywoływanych z odpowiednimi parametrami, aby na podstawie plik2 uzyskać plik1,
- analogicznie, aby uzyskać plik2, potrzebujemy do tego plik3 (ten dostarczany jest przez użytkownika).
Plik Makefile odczytywany jest przez polecenie make, które na jego podstawie wywołuje w odpowiedniej kolejności serię komend z sekcji polecenia. Makefile musi znajdować się w katalogu w którym wywołujemy polecenie make.
Dla przykładowego prostego programu w C, plik Makefile wygląda następująco:
plik: plik.o
gcc -o plik plik.o
plik.o: plik.c
gcc -c plik.cDla równie prostego, jednoplikowego, programu w Asemblerze:
plik: plik.o
ld -o plik plik.o
plik.o: plik.s
as -o plik.o plik.s3. Procesor IA-32 – dostęp do rejestrów, rozkazy i ich sufiksy
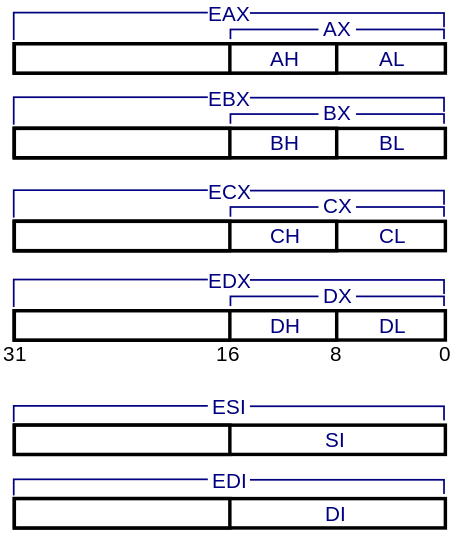
Na zajęciach poznaliśmy część rejestrów ogólnego przeznaczenia procesorów z rodziny IA-32. Były to 64-bitowe rejestry RAX, RBX, RCX, RDX, RDI, RSI oraz R8-R15. Oprócz dostępu do pełnych 64 bitów, istnieje także możliwość skorzystania z fragmentów tych rejestrów. I tak, rejestry EAX, EBX, ECX, EDX, ESI, EDI i R8D-R15D to najmniej znaczące 32 bity wymienionych wcześniej rejestrów. AX, BX, CX, DX, DI, SI oraz R8W-R15W to najmniej znaczące 16 bitów wymienionych rejestrów. Możliwy jest także dostęp do 8-bitowych fragmentów rejestrów, przy czym, dla każdego 64-bitowego rejestru dysponujemy dwoma takimi fragmentami – najmniej znaczące 8 bitów to rejestry AL, BL, CL, DL i R8L-R15L, a następne z kolei 8 bitów to rejestry AH, BH, CH, DH i R8H-R15H. Zmiana w każdej części rejestru powoduje zmianę w pozostałych.
Rozkazy które poznaliśmy na zajęciach i mieliśmy poznać przy okazji pisania zadań na następne:
| Rozkaz | Opis |
|---|---|
mov ŹRÓDŁO, CEL | kopiuje zawartość rejestru, zmiennej lub fragment pamięci do innego rejestru/zmiennej/fragmentu pamięci |
jmp ADRES/ETYKIETA | skok do instrukcji pod adresem podanym liczbowo lub do etykiety |
add A, B | dodaje A do B i zapisuje wynik do B |
adc A, B | dodaje A do B uwzględniając przy tym flagę przeniesienia ustawioną lub nie podczas poprzedniej operacji dodawania |
sub A, B | odejmuje A od B i zapisuje wynik do B |
sbb A, B | odejmuje A od B uwzględniając flagę przeniesienia z poprzedniego odejmowania |
mul LICZBA | mnoży zawartość rejestru A (np. RAX) przez wartość LICZBY (wartość zapisana w innym rejestrze) i wynik zapisuje do rejestru A |
div LICZBA | dzieli zawartość rejestru A przez LICZBĘ (wartość zapisaną w innym rejestrze), wynik zapisuje do rejestru A, a resztę z dzielenia do rejestru D |
not LICZBA | odwraca bity LICZBY |
or A, B | wykonuje logiczną operację OR dla każdego bitu A i B |
and A, B | wykonuje logiczną operację AND dla każdego bitu A i B |
xor A, B | wykonuje logiczną operację XOR dla każdego bitu A i B |
shl A, B | przesunięcie bitowe B o A w lewo (pomnożenie przez 2^A) |
shr A, B | przesunięcie bitowe B o A w prawo (podzielenie przez 2^A) |
cmp A, B | porównuje dwie liczby i ustawia odpowiednie flagi na podstawie których kolejne instrukcje wykonują skoki |
jl ADRES/ETYKIETA | jump if less – wykonuje skok jeśli B<A |
jle ADRES/ETYKIETA | jump if less or equal – B<=A |
jg ADRES/ETYKIETA | jump if greater – B>A |
jge ADRES/ETYKIETA | jump if greater or equal – B>=A |
je ADRES/ETYKIETA | jump if equal – B=A |
jne ADRES/ETYKIETA | jump if not equal – B!=A |
jz ADRES/ETYKIETA | jump if zero – B=0 |
jnz ADRES/ETYKIETA | jump if not zero – B!=0 |
jb ADRES/ETYKIETA | jump if below – B<A (bez znaku) |
ja ADRES/ETYKIETA | jump if above – B>A (bez znaku) |
Część instrukcji wykonujących operacje na rejestrach o ustalonej szerokości można zakończyć sufiksem bezpośrednio określającym z jakiej długości danymi mamy do czynienia. Nie jest to zazwyczaj wymagane, jednak jeśli w instrukcji nie ma odwołania do rejestru może być to konieczne. Dla operacji 64-bitowych sufiks to q (np. movq), dla operacji 32-bitowych – l, dla 16-bitowych – w i dla 8-bitowych – b.
4. Struktura programu w Asemberze
Kod w Asemblerze składa się z trzech sekcji. W sekcji danych .data umieszczamy definicje zmiennych wraz z ich zawartością. W sekcji .bss umieszczamy definicję zmiennych/buforów jeszcze niezainicjalizowanych danymi. W sekcji .text znajduje się kod programu.
Przykład:
.data
AAA = 1
bbb: .ascii "Hello World!\n"
bbb_len = .-bbb
.bss
.comm bufor, 512
.text
.globl _start
_start:
KOD PROGRAMUW sekcji danych .data zadeklarowana została zmienna AAA i przypisano jej wartość 1, następnie utworzono ciąg znaków o adresie początkowym bbb i długości bbb_len. W kolejnej sekcji – .bss znalazła się definicja buforu o długości 512 bajtów który jeszcze nie ma przypisanej wartości. W sekcji kodu .text wywołana jest etykieta _start i w niej można umieścić właściwe instrukcje.
5. Wywoływanie funkcji i “Hello World!”
Z poziomu kodu w Asemblerze przy pomocy przerwań systemowych można skorzystać z funkcji udostępnianych przez system operacyjny. W wersji 32-bitowej należy w tym celu umieścić odpowiednie parametry funkcji w kolejnych rejestrach – EAX, EBX, ECX, EDX, ESI, EDI, a następnie wywołać przerwanie int $0x80. Wynik działania funkcji zostanie załadowany do rejestru EAX. W wersji 64-bitowej jest to znacznie mniej intuicyjne – rejestry w których umieścić należy kolejne parametry funkcji to: RAX, RDI, RSI, EDX, R10 i R8. Wynik umieszczony zostanie w rejestrze RAX. Przerwanie wywołuje się rozkazem syscall.
Poniżej kod przykładowego programu wyświetlającego tekst “Hello World!” (wersja 64-bit):
.data
STDOUT = 1
SYSWRITE = 1
SYSEXIT = 60
EXIT_SUCCESS = 0
tekst: .ascii "Hello World!\n"
tekst_len = .-tekst
.text
.globl _start
_start:
# WYŚWIETLENIE TEKSTU - WYWOŁANIE SYSTEMOWE SYSWRITE
movq $SYSWRITE, %rax
movq $STDOUT, %rdi
movq $tekst, %rsi
movq $tekst_len, %rdx
syscall
# ZWROT WARTOŚCI EXIT_SUCCESS ("return 0;") - WYWOŁANIE SYSTEMOWE SYSEXIT
# W poniższy sposób należy zawsze zakańczać działanie programu, bez tego
# - mimo prawidłowego wykonania kodu, uzyskamy błąd: "Segmentation fault".
mov $SYSEXIT, %rax
mov $EXIT_SUCCESS, %rdi
syscall6. Program powtarzający to co wpisze użytkownik
Kolejnym programem napisanym na laboratorium jest modyfikacja poprzedniego programu, wczytująca do bufora textin ciąg znaków od użytkownika, a następnie go wyświetlająca. Poniżej kod:
.data
STDIN = 0
STDOUT = 1
SYSREAD = 0
SYSWRITE = 1
SYSEXIT = 60
EXIT_SUCCESS = 0
BUFLEN = 512
.bss
.comm textin, 512
.text
.globl _start
_start:
movq $SYSREAD, %rax
movq $STDIN, %rdi
movq $textin, %rsi
movq $BUFLEN, %rdx
syscall
# Rejestr RAX zawiera ilość wprowadzonych znaków.
# Zostanie on zaraz nadpisany, więc liczbę tą trzeba przenieść.
# Będzie ona potrzebna przy wywołaniu funkcji drukującej tekst.
movq %rax, %rbx
movq $SYSWRITE, %rax
movq $STDOUT, %rdi
movq $textin, %rsi
movq %rbx, %rdx
syscall
mov $SYSEXIT, %rax
mov $EXIT_SUCCESS, %rdi
syscall7. Program zmieniający wielkość liter i dostęp do pamięci
Kolejną modyfikacją kodu z laboratoriów, był program wczytujący od użytkownika ciąg znaków, zmieniający w nim wielkość liter i wypisujący ten ciąg na ekran. Należało tutaj zauważyć że wielkie i małe litery w kodach ASCII różnią się o wartość 0x20, w związku z tym po wykonaniu na kodzie litery operacji XOR 0x20 dostajemy literę o przeciwnej wielkości.
W programie po raz pierwszy pojawia się dostęp do fragmentów pamięci. Składnia offset(%base, %index, multiplier) pozwala odczytać lub zapisać ilość bajtów równą wartości multiplier pod adresem w pamięci równym offset + zawartość rejestru base + zawartość rejestru index pomnożoną przez wartość multiplier.
Poniżej kod programu:
.data
STDIN = 0
STDOUT = 1
SYSREAD = 0
SYSWRITE = 1
SYSEXIT = 60
EXIT_SUCCESS = 0
BUFLEN = 512
KONIEC_LINI = 0xA
.bss
.comm textin, 512
.comm textout, 512
.text
.globl _start
_start:
movq $SYSREAD, %rax
movq $STDIN, %rdi
movq $textin, %rsi
movq $BUFLEN, %rdx
syscall
# Przeniesienie długości wprowadzonego ciągu znaków
# do rejestru R8 oraz wyzerowanie rejestru RDI - licznika pętli
movq %rax, %r8
movq $0, %rdi
jmp petla
petla:
# Operacja XOR-owanie kolejnych liter
movb textin(, %rdi, 1), %al
xor $0x20, %al
movb %al, textout(, %rdi, 1)
# Ponowny przeskok do etykiety "petla", aż do wykonania
# operacji XOR dla wszystkich liter w buforze.
inc %rdi
cmp %r8, %rdi
jle petla
jmp wyswietl
wyswietl:
movq $SYSWRITE, %rax
movq $STDOUT, %rdi
movq $textout, %rsi
movq %r8, %rdx
syscall
mov $SYSEXIT, %rax
mov $EXIT_SUCCESS, %rdi
syscall8. Debugowanie
Jeśli z jakiś powodów napisana aplikacja nie działa prawidłowo, możemy skorzystać z debugera gdb. Należy wtedy podmienić nazwę pierwszej etykiety ze _start na main (w obu miejscach) oraz kompilować program z flagą -gstabs. Aplikację uruchamiamy poleceniem gdb NAZWA_PLIKU_WYKONYWALNEGO. W debuggerze możemy korzystać z poleceń:
break ADRES/ETYKIETA– zatrzyma wykonywanie programu w momencie dojścia do danego adresu/etykiety,run– uruchomi program,info registers– wyświetli informacje o zawartości rejestrów,x/123AB &ADRES/ZMIENNA– wyświetli zawartość pamięci począwszy od podanego adresu/zmiennej.123to ilość fragmentów o wielkościA(b – 8 bitowych, h – 16 bitowych, w – 32 bitowych) do wyświetlenia.Bto sposób reprezentacji tych danych: c – znaki ASCII, d – liczby dziesiętne, x – liczby heksadecymalne. Przykład:x/50bc &textout– wyświetli 50 znaków ASCII (liter) z buforatextout.next/step– wznawia wykonywanie programu po zatrzymaniu,quit– wyłącza debugger.
Zauważ że skok ja != jg. Któreś z nich jest unsigned. W dokumentacji pisze który ;)