- Create new MySQL database.
- Run Django migrations on the new database. This will require you to change settings of the project.
python3 manage.py migrate - Disable key checks on MySQL server.
SET GLOBAL FOREIGN_KEY_CHECKS = 0; - Execute the query on MySQL database. Then, execute the results of this query as another query. This will make room for Postgres encoded UUID’s (with four dashes inside).
SELECT CONCAT('ALTER TABLE ', a.table_name, ' MODIFY COLUMN ' , a.column_name, ' CHAR (36);') FROM information_schema.columns a WHERE a.table_schema = 'DB_NAME' AND a.column_type = 'char(32)'; - Execute the queries on MySQL database. This will enable MySQL to store users and groups names in case-sensitive manner.
ALTER TABLE auth_user CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_cs; ALTER TABLE auth_group CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_cs; - Using DBeaver export the data from the PostgreSQL database into MySQL one.
- Execute the query on MySQL database. Then, execute its results. This will convert the Postgres encoded UUID’s (with dashes) into what Django expects to be in the MySQL database (UUID’s with no dashes inside).
SELECT CONCAT('UPDATE ', a.table_name, ' SET ' , a.column_name, ' = REPLACE(' , a.column_name, ', "-", "");') FROM information_schema.columns a WHERE a.table_schema = 'DB_NAME' AND a.column_type = 'char(36)'; - Execute the query on MySQL database. Then, execute the results of this query. This will remove the space needed for four unnecessary dashes from the UUID fields.
SELECT CONCAT('ALTER TABLE ', a.table_name, ' MODIFY COLUMN ' , a.column_name, ' CHAR (32);') FROM information_schema.columns a WHERE a.table_schema = 'DB_NAME' AND a.column_type = 'char(36)'; - Enable key checks on MySQL server:
SET GLOBAL FOREIGN_KEY_CHECKS = 1; - Start the Django app and check is everything working.
Autor: Aleksander Kurczyk
Opracowanie pytań na obronę MGR INF ISK 2019
S1. Modelowanie sieci komputerowych z wykorzystaniem przepływów wieloskładnikowych
Rozwiązywanie problemu optymalizacji sieci polega na: sformułowaniu problemu, jego zmodelowaniu (stworzeniu opisu matematycznego) oraz jego optymalizacji.
Topologia sieci komputerowej zazwyczaj modelowana jest w postaci grafu, którego wierzchołkami są urządzenia sieciowe (routery, przełączniki, komputery, etc.), a krawędziami media transmisyjne. Grafy te posiadają ograniczenia zarówno na węzłach, jak i na krawędziach – np. przepustowość.
Topologię sieci optymalizuje się zgodnie z funkcją celu, którą może być np.: minimalizacja kosztów budowy sieci albo zwiększenie niezawodności sieci.
Inżynieria Oprogramowania – opracowanie zagadnień na egzamin
Definicja Inżynierii Oprogramowania
Wiedza techniczna dotycząca faz cyklu życia projektu, mająca na celu uzyskanie wysokiej jakości oprogramowania.
Przyczyny Kryzysu Oprogramowania
- Duża złożoność systemów informatycznych
- Niepowtarzalność przedsięwzięć
- Nieprzejrzystość procesu budowy oprogramowania
- Pozorna łatwość wytwarzania i dokonywania poprawek
Definicja projektu
Zarządzany zbiór zadań zmierzających do jednego celu, wykonywany przy określonych ograniczeniach.
Cykl życia projektu (SDLC – System Development Life Cycle) – sekwencja następujących po sobie faz projektowych, zmierzających do wytworzenia oprogramowania
Czytaj dalej Inżynieria Oprogramowania – opracowanie zagadnień na egzamin
Architektura Komputerów 2 – Laboratorium nr 6 – Jednostka zmiennoprzecinkowa (FPU)
Rejestry jednostki zmiennoprzecinkowej
Koprocesor dysponuje ośmioma 80-bitowymi rejestrami zmiennoprzecinkowymi i trzema 16-bitowymi rejestrami kontrolnymi (control word, status word i tag word). Rejestry zmiennoprzecinkowe połączone są w stos. Możemy wczytywać do nich wartości rozkazami fld (Fpu LoaD) oraz pobierać z nich wartości – fstp (FPU STore and Pop). Mamy do nich dostęp poprzez nazwę ST i numer rejestru – ST(n). Wartości zawsze wstawiane są do rejestru ST(0), a wszystkie pozostałe rejestry zmieniają wtedy swoją numerację – 0 przechodzi na 1, 1 na 2 itd. Analogicznie podczas pobierania wartości z tego “stosu”, pobierana jest wartość z rejestru ST(0), a pozostałe zmieniają numerację w przeciwnym kierunku.
Architektura Komputerów 2 – Laboratorium nr 5 – Łączenie kodu C i Asemblera
1. Dostęp do funkcji języka C z poziomu Asemblera
Aby wywołać funkcję napisaną w C z kodu Asemblerowego należy umieścić jej argumenty całkowite (liczby lub wskaźniki na adresy w pamięci) kolejno w rejestrach RDI, RSI, RDX, RCX, R8, R9, argumenty zmiennoprzecinkowe w rejestrach XMM0-XMM7 i wywołać tą funkcję korzystając z rozkazu call. Jeśli przekazujemy argumenty zmiennoprzecinkowe, wtedy do rejestru RAX musimy również wpisać ich ilość.
Przykład wywołania funkcji:
mov $1, %rax # Ilość argumentów zmiennoprzecinkowych
# - przesyłany jest jeden parametr i znajdzie się on
# w rejestrze XMM0
mov $25, %rsi # Pierwszy parametr - typu całkowitego
mov $75, %rdi # Drugi parametr - typu całkowitego
movss liczba, %xmm0 # Trzeci parametr - typu zmiennoprzecinkowego
# skopiowany z 4-bajtowej komórki w pamięci
call funkcja # Wywołanie funkcjiArchitektura Komputerów 2 – Laboratorium nr 4 – Stos i funkcje
Stos procesora
Stos jest strukturą danych, w której dane dokładane są na wierzch stosu i z wierzchołka stosu są pobierane. W procesorach z rodziny x86 stos znajduje się w górnej części pamięci operacyjnej, a dane umieszczane są na nim w kierunku odwrotnym – tj. od większego adresu do mniejszego.
Aby odłożyć zawartość rejestru na stos, korzystamy z rozkazu push REJESTR. Aby ściągnąć zawartość ostatniego elementu ze stosu do rejestru, używamy rozkazu pop REJESTR.
Rejestr przechowujący wskaźnik na ostatni element stosu to RSP. Zwiększenie zawartości tego rejestru o 8 powoduje “usunięcie” ze stosu ostatniej wartości. Dokładniej mówiąc wartość ta nie jest usuwana, ale podczas następnego odłożenia wartości na stos zostanie ona nadpisana.
Czytaj dalej Architektura Komputerów 2 – Laboratorium nr 4 – Stos i funkcjeArchitektura Komputerów 2 – Laboratorium nr 3 – Dostęp do plików przez wywołania systemowe
Obsługa plików Linuksowymi wywołaniami systemowymi
Aby odczytać lub zapisać dane do pliku, z poziomu języka Asembler, musimy posłużyć się wywołaniami systemowymi otwierającymi plik do odczytu i/lub zapisu oraz, po skończonej pracy z plikiem, zamykającymi go, a następnie odczytać lub zapisać dane w sposób identyczny jak ma to miejsce w przypadku odczytu danych od użytkownika z klawiatury lub wyświetlania komunikatów na ekran. Zamiast strumieni (wirtualnych plików) STDIN i STDOUT podaje się tutaj identyfikator otwartego pliku. Podczas otwierania pliku należy wyspecyfikować co zamierzamy z nim zrobić – plik możemy otworzyć tylko do odczytu, do zapisy, do zapisu i odczytu, do dopisywania, etc. W przypadku gdy spróbujemy otworzyć nieistniejący plik do zapisu, plik ten może zostać utworzony. Należy wtedy sprecyzować z jakimi prawami dostępu ma on zostać utworzony podając ich wartość liczbową.
Czytaj dalej Architektura Komputerów 2 – Laboratorium nr 3 – Dostęp do plików przez wywołania systemoweArchitektura Komputerów 2 – Laboratorium nr 2 – Pętle, podstawowe operacje logiczne i arytmetyczne
Zadanie nr 1
W ramach zadania domowego mieliśmy rozwinąć kod z pierwszych zajęć zamieniający litery małe na wielkie i odwrotnie. Nowy program dodaje do kodu ASCII każdej małej litery wartość 6 oraz do kodu każdej wielkiej litery wartość 8. Pozostałe znaki nie są zmieniane.
Czytaj dalej Architektura Komputerów 2 – Laboratorium nr 2 – Pętle, podstawowe operacje logiczne i arytmetyczneArchitektura Komputerów 2 – Laboratorium nr 1 – Podstawy pisania programów w języku Asembler
1. Wprowadzenie do Linuksa i pracy w laboratorium
W trakcie zajęć zapoznaliśmy się z podstawami poruszania się w środowisku Linux – poleceniami mkdir, cd, touch, pwd, whoami, cat, ls, mv, rm, cp, adresowaniem względnym i bezwzględnym oraz edytorami vim, mcedit i nano. Omówiliśmy także sposób zdalnego logowania się do laboratoryjnego serwera na którym wykonywać będziemy zadania. Ponieważ w sprawozdaniu opisać mieliśmy jedynie nowe dla nas zagadnienia, a ja na co dzień korzystam z systemu Linux, pozwolę sobie pominąć tą część.
2. Kompilacja w konsoli, linkowanie, program make i plik Makefile
Aby przećwiczyć kompilację programów w konsoli, napisaliśmy prosty program wyświetlający napis “Hello World!” w języku C i skompilowaliśmy go ręcznie wywołując polecenia:
gcc -c plik.c
gcc -o plik plik.oTeoria obwodów – Ćwiczenia 4 – Źródła o różnych pulsacjach i dwójniki
Źródła o różnych pulsacjach
Przy obliczaniu prądu lub napięcia w obwodach z wieloma źródłami o różnych pulsacjach, należy obliczyć osobne wyniki dla każdej pulsacji i dodać je do siebie już po zamianie na postać funkcji. Obliczając poszczególne przypadki zwieramy wszystkie źródła napięciowe (zamieniamy je na zwykłe połączenie) oraz rozwieramy wszystkie źródła prądowe o innej pulsacji (rozcinamy obwód).
Obliczanie impedancji dwójnika dla max mocy
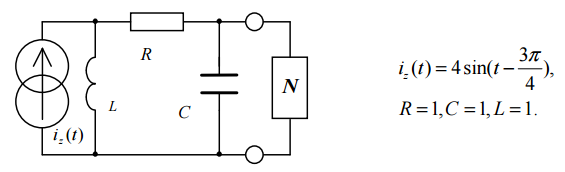
Czytaj dalej Teoria obwodów – Ćwiczenia 4 – Źródła o różnych pulsacjach i dwójniki